RabbitMQ学习笔记
相关概念
1.生产者
一个发送消息的程序就是一个生产者:

2.队列
一个队列就是rebbitmq中的邮箱。消息只能存储在队列中,队列受到服务器的内存和硬盘大小的限制,是一个巨大的消息缓冲区。许多生产者可以发送消息给同一个队列,许多消费者
可以从这同一个队列中接收消息。我们这样表示一个队列:

3.消费者
一个消费者就是一个等待接收消息的程序:

注意:producer consumer broker可以部署在不同的服务器上。一个应用程序可以同时是生产者和消费者。 在rabbitmq中,消息不直接发送给queue,而是通过exchange来完成。exchange可以用默认的,不指定的话就是默认的。exchange一方面从producer接收消息,另一方面将消息存入queue。exchange必须明确知道如何处理message,是要存入一个专门的队列,还是存入许多个队列?还是应当丢弃?这些规则由exchange type来确定(direct/topic/headers/fanout)。
fanout exchange:广播收到的消息给它知道的所有队列
rabbitmq tutorial
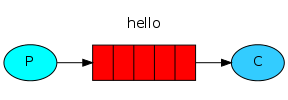
例子一 queue
send.py(生产者) receiver.py(消费者)
例子二 work queue
worker.py(消费者) new_task.py(生产者)
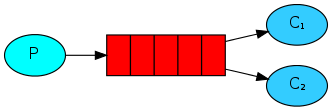
多个worker,一个producer
例子三 发布/订阅
简单日志系统 emit_log.py receives_log.py
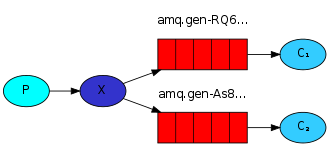
fanout exchange
exchange和queue之间的关系称为bind
发布消息前必须先声明exchange,因为发消息给不存在的exchange是不允许的。
例子四 路由
给例子三的日志系统加上一个特性:允许订阅消息的子集。例如只将critical error messages存入日志文件,而将所有日志消息打印到控制台。
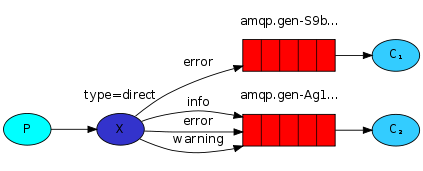
绑定:queue对这个exchange的消息感兴趣。
routing_key 这个例子里面是错误等级
queue_bind的routing_key是绑定key
例子五 主题
新需求:在日志系统中不仅需要根据错误等级来订阅消息,也需要根据产生日志的源来订阅消息。需要使用topic类型的exchange。
topic exchange
主题的样例:stock.usd.nyse nyse.vmw quick.orange.rabbit(最长255字节)
topic exchange的实现逻辑和direct exchange类似——一条有特定routing key的消息将被发送给所有有相应的bingding key的队列。
- *代表一个单词
- #代表零个或多个单词
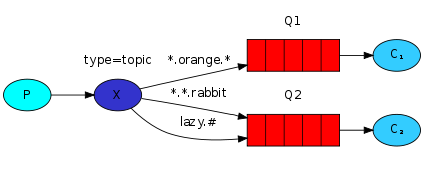
上图中topic exchange的routing_key定义规则:
例子六 RPC
本例中,我们将使用rabbitmq来构建一个RPC系统:一个客户端和一个可扩展的服务端。构建一个dummy rpc服务,返回佩波那契数列。
client interface
为了说明rpc服务如何使用,我们将创建一个简单的客户端类。这个类将提供一个call方法,用来发送rpc请求并阻塞直到收到应答。
注意:rpc误用会导致不可预测问题。
使用场景:
- 哪个方法是本地调用,哪个方法是远程调用非常的明显的情况
- 写文档,模块间的依赖要清晰化
- 处理错误样例。如果一个rpc服务长时间挂掉了,那么客户端如何表现
若上述几方面存在疑惑,那么避免使用rpc,而应该使用异步管道来代替rpc
callback queue
总的来说,rabbitmq的rpc很简单:一个客户端发送一个请求消息,一个服务端回复一个响应消息。为了接收到响应,客户端发起请求时要带上回调队列的地址。
消息属性
AMQP 0-9-1协议预定义了消息的14个属性,大部分属性很少使用,除了这些属性较常用:
- delivery_mode:标记一个消息为持久化消息(值为2)或临时消息(任意其他的值)
- content_type:用来描述编码的mime类型。例如JSON类型,content_type设置为application/json
- reply_to:通常用来指定回调队列
- correlation_id:用于关联rpc响应和请求
消息属性概览
- content_type : 消息内容的类型
- content_encoding: 消息内容的编码格式
- priority: 消息的优先级
- correlation_id:关联id
- reply_to: 用于指定回复的队列的名称
- expiration: 消息的失效时间
- message_id: 消息id
- timestamp:消息的时间戳
- type: 类型
- user_id: 用户id
- app_id: 应用程序id
- cluster_id: 集群id
- Payload: 消息内容
Correlation_id
为每一个rpc请求创建一个回调队列,是相当低效的,好在有一个更好的方法:每个客户端创建单个回调队列。这带来一个新的问题:队列收到响应消息时不知道是对应哪个请求的。这时,correlation_id就派上用场了。每个请求都设置一个唯一的correlation_id,之后,当我们在回调队列中收到消息时,我们将查看这个属性,这样就可以知道这个响应是对应哪个请求的。如果发现是未知的correlation_id,那么就可以安全地丢弃掉这条消息,因为它不属于任何一个请求。
你或许会问,为什么我们要丢弃这条未知消息,而不是返回一个错误呢?这和服务端的竞态条件有关。尽管并不期望如此,但rpc服务在发送应答后还是可能在发送响应前会挂掉。若是如此,重启的rpc服务会重新处理请求。这就是为什么我们必须在客户端优雅地处理重复响应,rpc在理想情况下应该是幂等的。
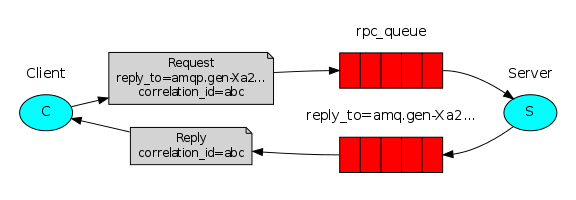
上图的rpc如此运作
- 启动客户端的时候,创建一个匿名的唯一的回调队列
- 客户端发送的rpc请求消息带两个属性:reply_to,指定回调队列;correlation_id,对每个请求都是一个唯一值
- 请求发送给rpc_queue
- rpc worker等待请求。当请求到达时,worker处理请求并将结果返回给reply_id指定的queue
- 客户端在回调队列等待数据。当消息到达时,它先核对correlation_id。如果和请求的一致,则返回响应给应用程序
rabbitmq消息持久化
- 队列持久化需要在声明队列时添加参数 durable=True,这样在rabbitmq崩溃时也能保存队列
- 仅仅使用durable=True ,只能持久化队列,不能持久化消息
- 消息持久化需要在消息生成时,添加参数 properties=pika.BasicProperties(delivery_mode=2)